Yusuf Birader
A No Nonsense Guide to Unicode
“Software is eating the world”, Marc Andreessen famously declared in 2011.
The ability to represent text in any of the world’s languages is crucial to modern applications.
The Unicode standard provides this capability, improving upon early character sets such as ASCII, which ignore the 94% of the world’s non-English speaking inhabitants.
Understanding Unicode is key to working with text in modern digital systems.
The Basics of Character Encodings
Let’s start from the beginning.
It’s no mystery that all data in a computer is stored as bits, commonly represented by 1s and 0s.
To represent a number, we simply convert the number into its corresponding base-2 (binary) form.
But what about text?
How do we represent the letter a, or z, or even emojis like 😁?
What we need is a mapping between characters and binary numbers. The mapping defines how each character can be represented as a binary number that can be stored in memory.
A set of mappings between characters and binary values is known as a character set.
In other words, a character set defines how a set of characters are encoded into a corresponding binary form.
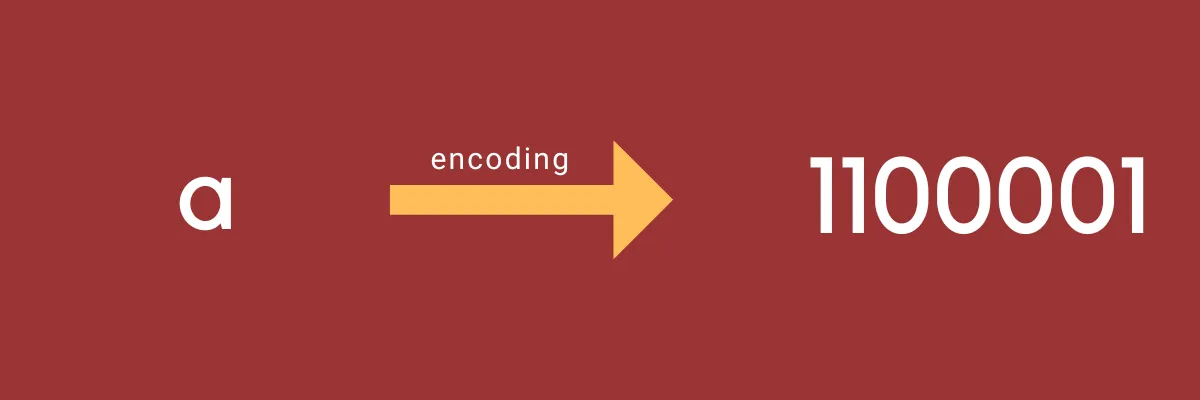
Computers represent digital text by encoding each character as a binary digit. A character set defines the specific binary digit that corresponds to a particular character. The process of mapping a character to a binary digit is known as encoding.
Many character sets/encodings exist- different sets generally use different encoding schemes.
But they all exist for one reason- to map characters to computer-friendly binary digits.
The existence of many character sets with different encoding schemes can be problematic. If two computers don’t agree on a common encoding scheme, the binary output of one computer cannot be decoded back into a character by another.
When a computer can’t recognise a character, most operating systems use a dummy character, usually a question mark in a box, to represent the unknown character. The cause of this is simple- the computer cannot decode the binary form to a character to display. In other words, it does not recognise the encoding scheme of the character.
What’s needed is a standard character set- one that defines a mapping that all computers agree upon.
So that the letter a on one computer is also a on another computer. And not, say 👙!
ASCII An early attempt to create a standardised character set resulted in the creation of the American Standard Code for Information Interchange, also known as ASCII.
ASCII is a 7-bit (usually 1 byte) character set containing 128 characters. The characters are based on the English alphabet.
To make the math easier, ASCII-aware systems usually map each character to 8 bits, or 1 byte [1].
That gives ASCII the nice property that the number of characters equals the number bytes.
But ASCII is very limited- its characters are based on the English alphabet. It completely ignores characters from other scripts like Chinese, Arabic, and Cyrillic.
As software started to escape the confines of the English-speaking world, a new standard was needed. One that recognised the world’s languages, scripts and thirst for emojis.
Unicode
In response to the limitations of ASCII, the Unicode standard was developed.
Background To understand Unicode, its important to get the terminology correct.
With ASCII, which only uses the English alphabet, the term character is used to define an atomic, human-readable character.
But in the context of non-English scripts, which may include accented words, complex glyphs, and coloured emojis, what really is a character?
Is it an a or á or even a plus an accent modifier?
To clear up this ambiguity, Unicode introduces three terms; code point, grapheme, and text. This allows us to precisely identify different textual attributes.
Firstly, a code point is a numeric representation of a particular atomic unit of textual information. For example, in Unicode, the letter a has the code point U+0061, the letter A has the code point U+0041, and the accented accent modifier has code point U+0769. Remember that a code point is not the same as a character- a single human-readable character may be made up of several code points.
Secondly, a grapheme is the combination of one or more code points which represents a single, graphical unit that a reader recognises. For example, the letter é is a grapheme which comprises of the code points U+0101 and U+0769.
Thirdly, text is a sequence of one or more graphemes.
In other words, we now have code points that represent an atomic unit of textual information, we combine code points to get graphemes i.e. a human-readable character, and we combine graphemes to get text.
That leaves one last piece of the unicode puzzle- how do we represent the code points themselves in binary?
Unicode Encoding Schemes
In ASCII, we take the simple approach that a single ASCII character always maps to a single byte.
In Unicode, a single Unicode grapheme/character can be made up of several code points and a single code point may be represented by multiple bytes. That means that a single human-readable unicode character may range from a single byte to a concatenation of many bytes.
Whilst the ASCII encoding scheme is refreshingly simple, we need something more scalable when working with Unicode.
UTF-32
A common scheme for encoding Unicode code points is known as UTF-32.
In UTF-32, each code point is mapped to 4 bytes (32 bits).
The advantage of this scheme lies in its simplicity.
Every character is represented by the same number of bytes. This means that text is easier to parse and the size of text is easy to reason about- simply count the number of graphemes/characters and multiply by 4.
However, this simplicity comes at a cost.
UTF-32 is very memory-inefficient. Most popular characters, namely those in the English alphabet can be represented by a single, 1 byte code point. Using UTF-32 means such characters must be padded with 3 bytes of useless zeros to bring the total per character to the required 4 bytes. For the standard ASCII characters, this makes UTF-32 encoding 4x more wasteful than ASCII.
We need something better.
UTF-8
The need for an encoding scheme which lies between the frugality of ASCII and the excesses of UTF-32 led to the creation of UTF-8, which has become one of the most popular unicode code point encoding schemes [2].
In UTF-8, the amount of bytes that a given code point maps to is variable- simple code points such as those that represent the English alphabet map to a single byte. The largest code points map to 4 bytes.
This variation in the size of a single character means that parsing UTF-8-encoded strings is slower and more complex.
But it does ensure that text, of all kinds, is represented in a memory efficient way.
And that’s not even the best bit.
In UTF-8, the first 126 characters have the same, single-byte code point values as the corresponding ASCII values. That means that UTF-8 is backwards compatible- any ASCII text is valid UTF-8 text.
Engineers everywhere can breathe a sigh of relief that their early ignorance of internationalisation won’t be punished.
Summary
Here’s a quick summary of what you need to know.
At a most basic level, computers only understand bits. These bits have no intrinsic meaning. To represent text, we need an encoding. The encoding scheme defines how each human-readable character that we want to use maps to a unique sequence of bits. The set of all characters and their corresponding encodings represents a character set.
ASCII is a simple character set for the English alphabet, where a single character is represented by a single byte.
Unicode is a larger character set that can be used to represent any character in existence. It defines a set of code points that can be combined to form human-readable characters i.e. graphemes. The code points are encoded, most commonly by the UTF-8 scheme, where the number of characters does not necessarily equal the number of bytes (this only holds true for the first 126 ASCII characters).
Unicode in the Wild
So that’s the theory. But what about the practice?
A critical piece of this is that programming languages manipulate strings at the byte level. This means that its critical to know the encoding scheme used and how different language constructs can interact with text in different ways.
Read on to find out how Unicode is used in the wild: Bytes, Runes, and Strings: How Text Works in Go
Notes
[1]- Most computers use 8-bits since its easier to represent a power of 2.
Subscribe
If you'd like to be kept in the loop for future writing, you can join my private email list. Or even just follow me on X/Twitter @yusufbirader.