Yusuf Birader
Building Terminal: A Case Study
Overview
Terminal is a web-based tool for testing and debugging webhooks. It provides an easy and convenient way for developers to test the behavior of their applications when receiving webhook requests. With Terminal, users can quickly set up a virtual endpoint to receive incoming webhooks, and inspect the details of each request, such as the headers and payload, in real-time.
This allows for fast and efficient testing and debugging of webhook integrations, without the need to set up a full-fledged server or deal with the complexities of manual testing.
Introduction
The Core Problem
Applications do not exist in isolation. The functionality which they offer is only made possible by a symphony of real-time data transfer with a variety of third-party services.
Take payments as an example. When a user signs up for your service, we often have to submit a request for payment processing to a third-party service like Stripe.
Only once we know the payment has been successfully processed can we subscribe the user to our service.
The ability of one service being able to notify another service is the foundation of modern event-driven architectures, facilitating data integration, automation, event notifications, and real-time monitoring.
In other words, enabling data transfer between applications is a critical component of modern application development.
Solutions
Before the existence of webhooks, applications often used periodic polling to check for updates from other applications. In this setup, one application would send a request to another at regular intervals to retrieve any new data.
This approach does have significant drawbacks.
For example, polling can be resource-intensive, since each poll requires processing power and network resources. Additionally, it introduces latency into the flow of data, as the receiving application has to wait for the next poll to receive updates.
To overcome the limitations of polling, more complex systems such as message queues or real-time communication protocols such as WebSockets can be used. However, these can be difficult to set up and maintain.
Webhooks
A simpler and highly scalable solution to the above problem is to use webhooks.
Webhooks provide a more efficient solution by allowing one application to send a notification to another as soon as an event of interest occurs.
The process of setting up webhooks typically involves the following steps:
-
Determine the event: The first step in setting up webhooks is to determine the event that should trigger the webhook. This could be a customer order being placed, a form being submitted, or any other action that occurs within the application.
-
Set up the receiving endpoint: The next step is to set up a URL as the receiving endpoint for the webhook. This is the URL that the webhook will send the data to when the specified event occurs. Configure the webhook: In the application that will be sending the webhook, the webhook needs to be configured. This involves specifying the event that should trigger the webhook, and the URL of the receiving endpoint.
-
Test the webhook: After the webhook is set up, it’s important to test it to ensure that it’s working correctly. This can be done by triggering the specified event and inspecting the data that was sent to the receiving endpoint.
-
Deploy the webhook: Once the webhook has been tested and is confirmed to be working correctly, it can be deployed to a live environment. The process of implementing webhooks has a few aspects which can make testing and debugging webhooks difficult.
These include:
- The need for URL endpoints- we need to have already defined the receiving endpoint before we can test and inspect the webhook request.
- The need for a running server- we need to have a running production server with a publicly accessible IP. If we’re running in a local development environment, we would need a tool like ngrok to provide a public ingress point. This adds additional complexity and still requires a server to be active to accept requests. These requirements make it difficult for developers to rapidly test and debug webhook payloads.
A Better Way
To overcome these limitations, we derived a set of feature requirements for a service that allows rapid testing and debugging of webhook payloads.
A user should be able to:
- Generate virtual, unique public URL endpoints that can be used to register webhooks with a variety of third-party services. In the context of Terminal, a given URL endpoint is known as a bucket.
- View and inspect the requests that have been sent to a given endpoint in real time, including inspection of the request headers, method, payload and other meta-data.
- Allow a given endpoint, and the requests sent to it to be shared with others, making it easy to collaborate on testing and debugging integrations.
Architecture
After considering our requirements and the potential access patterns of users, we derived the following high-level architecture.
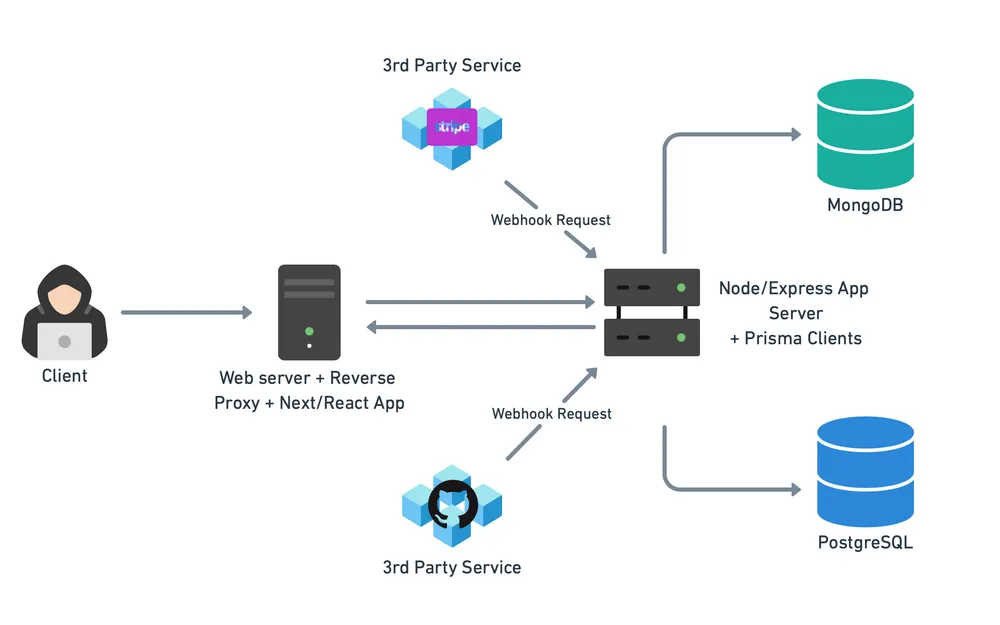
The architecture facilitates the following application flow.
A user can sign up, login, and can read, create, update and delete their existing buckets i.e. virtual endpoints via the Next.js/React frontend.
Users can register a given URL as a webhook to a third-party service of their choice. Within each bucket, users can view all webhook events which were sent to that endpoint and inspect the request data including headers. Users can also share buckets with multiple users.
This data is read and modified over standard HTTP with a backend Node/Express server.
The Node/Express backend is responsible for listening for incoming webhook requests to a particular URL endpoint. The server verifies that a bucket defined by the endpoint exists, and if so, persists the relevant data in the database(s). Upon user request, the server retrieves the relevant event data from the server via the Prisma clients, which can then served to the user.
Database Choice
Initially, when deciding on a database for our system, we had considered using a Postgres database to persist all data. This was based on the assumption that our applications would be storing primarily structured data such as user information, a registry of bucket endpoints etc. A relational model would allow us to impose a rigid schema, ensuring consistency.
However, after closely examining the webhook requests from various third-party providers, we realized that there was no standardization in the format of these requests. The payload returned has no fixed schema and often differed significantly between providers.
This made it difficult to store and process the data in a structured manner using a traditional relational database like Postgres. As a result, we decided to use a NoSQL document database in the form of MongoDB which allowed us to store the unstructured, schema-less data in a flexible format. This proved to be a better choice as it provided us with the flexibility that our system required to effectively handle the diverse data generated by web hook requests from various sources.
Our final data model is as follows:
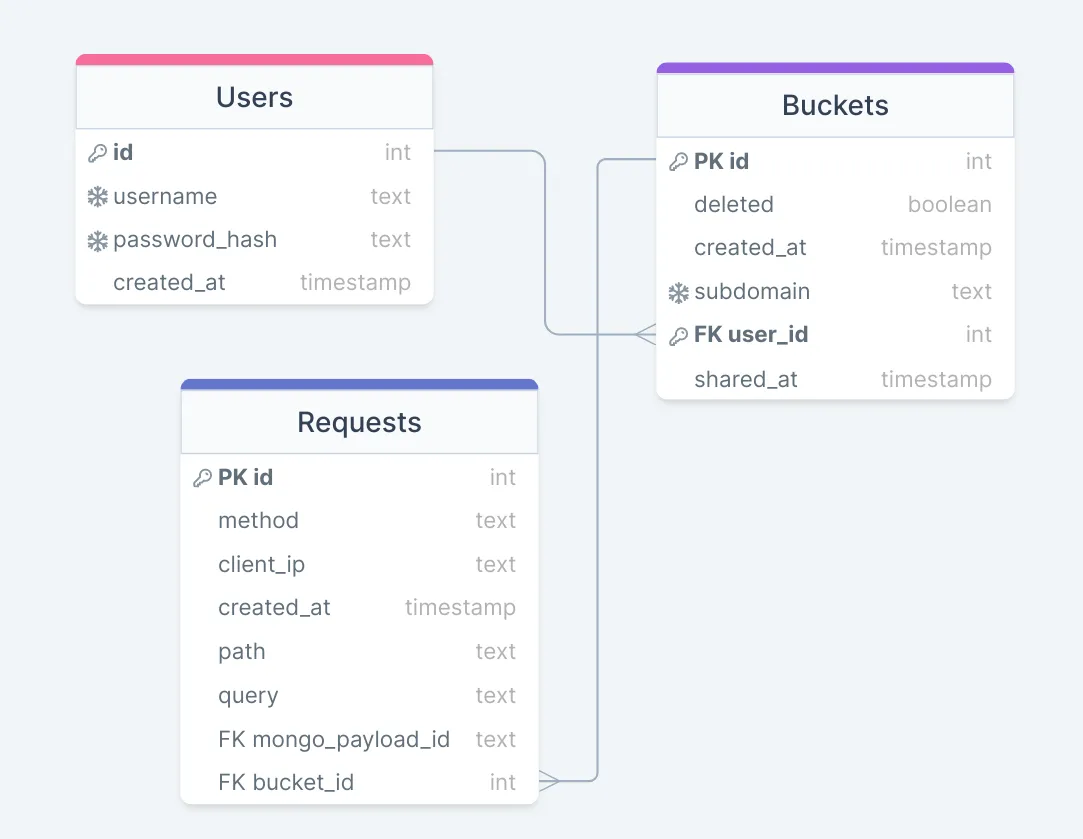
Note that whilst we stored the unstructured payload in MongoDB, we stored all fields which are common between requests such as HTTP methods, headers and other request meta-data in Postgres. This ensured that in the event that only request meta-data was required, the entire BSON payload would not need to be parsed.
Additionally, we decided to employ a soft-deletion model for deleting buckets. This allows easy recovery of data if needed. Whilst this can result in increased database size as deleted records are not physically removed from the database, we believed the added benefit of easily recovering data was more beneficial. This is because the database size is not expected to very large and thus performance considerations are less important than data recovery.
Interfacing with the Databases
To interface with the databases, we decided to use Prisma.
Prisma is an ORM (Object Relational Mapper) tool that provides a high-level, type-safe API to interact with databases like Postgres and MongoDB. By using Prisma, we could write database queries in a more natural and intuitive way, without having to worry about low-level details such as SQL syntax or connection management. This not only reduces the risk of errors in the code, but also makes it easier to maintain and evolve the database schema over time. Additionally, Prisma abstracts away the underlying database technology. This allowed us to use a consistent API to interact with both the Postgres and MongoDB database. It also means that our query logic is independent of a specific database. Thus, we could replace a database for another by simply using a different Prisma connector, leaving all query logic untouched.
Improving the Current Architecture
Whilst the above architecture provided a reliable solution to inspecting and debugging webhooks, we recognised the potential for improvement. Our updated architecture is:
Real-time Updates
In the current architecture, a user would have to manually poll the server in the form of repeated page refreshes to see the latest web hook requests. This was suboptimal. To address this limitation, we implemented web sockets between the client and the server. This allowed for real-time communication between the client and server, meaning that any web hook request would be immediately displayed to the user as soon as it was received. By using web sockets, we were able to provide a more seamless and efficient solution for viewing web hook requests, as the user no longer needed to manually refresh the page to see the latest updates.
Backend Server Overloading
In the event of a large number of webhook requests, we realised that that backend server would start to experience performance degradation and slowdowns. In order to mitigate this, we decided to implement message queue on the backend. A message queue is a type of software architecture pattern that allows for the exchange of messages between applications in a reliable and scalable manner. After our evaluating our use case, we chose RabbitMQ as our implementation due to its simplicity and lightweight nature.
By using a message queue, we were able to distribute the processing of web hook requests across multiple services, thereby reducing the burden on the backend server and improving overall performance. This also allowed us to ensure that web hook requests were processed in a reliable and consistent manner, as the message queue was able to store and process incoming requests even if the backend server was experiencing high levels of traffic.
Future Work
Whilst the current implementation of Terminal fulfils our original aim, there are several additional improvements that could be made including:
- Improved User Interface: A more flexible user interface where request payloads can be shown in different formats such as raw format, pretty print etc.
- Enhanced Bucket Management: Providing more options for managing buckets, such as the ability to set expiration dates, to archive buckets, or to limit the number of requests can help users better manage their data.
- Direct Integration with popular third-party services: currently, users must manually create a bucket and register the corresponding URL endpoint in their third-party service before they can start receiving requests. To improve this workflow, we could provide pre-built buckets which automatically register with the most popular services such as Github, Stripe etc.
Subscribe
If you'd like to be kept in the loop for future writing, you can join my private email list. Or even just follow me on X/Twitter @yusufbirader.